
GPT-style tokenizers encode leading spaces as meaningful statistical markers, so “stable” and “ stable” are treated differently. Understanding this distinction is key for prompt engineering and anticipating model behavior.
When I first explored GPT-2 token outputs, I noticed something that puzzled me: the same word could produce different tokens depending on the preceding space. At first, it felt like an unnecessary quirk, but it turned out to be an elegant statistical solution to token reuse and context encoding.
The tokenizer does not merely split text on spaces. Instead, it learns frequent patterns and encodes whitespace as part of those patterns. This approach allows common words to appear as single tokens while still enabling subword reuse inside larger, rare words.

Leading Spaces Signal Word Boundaries
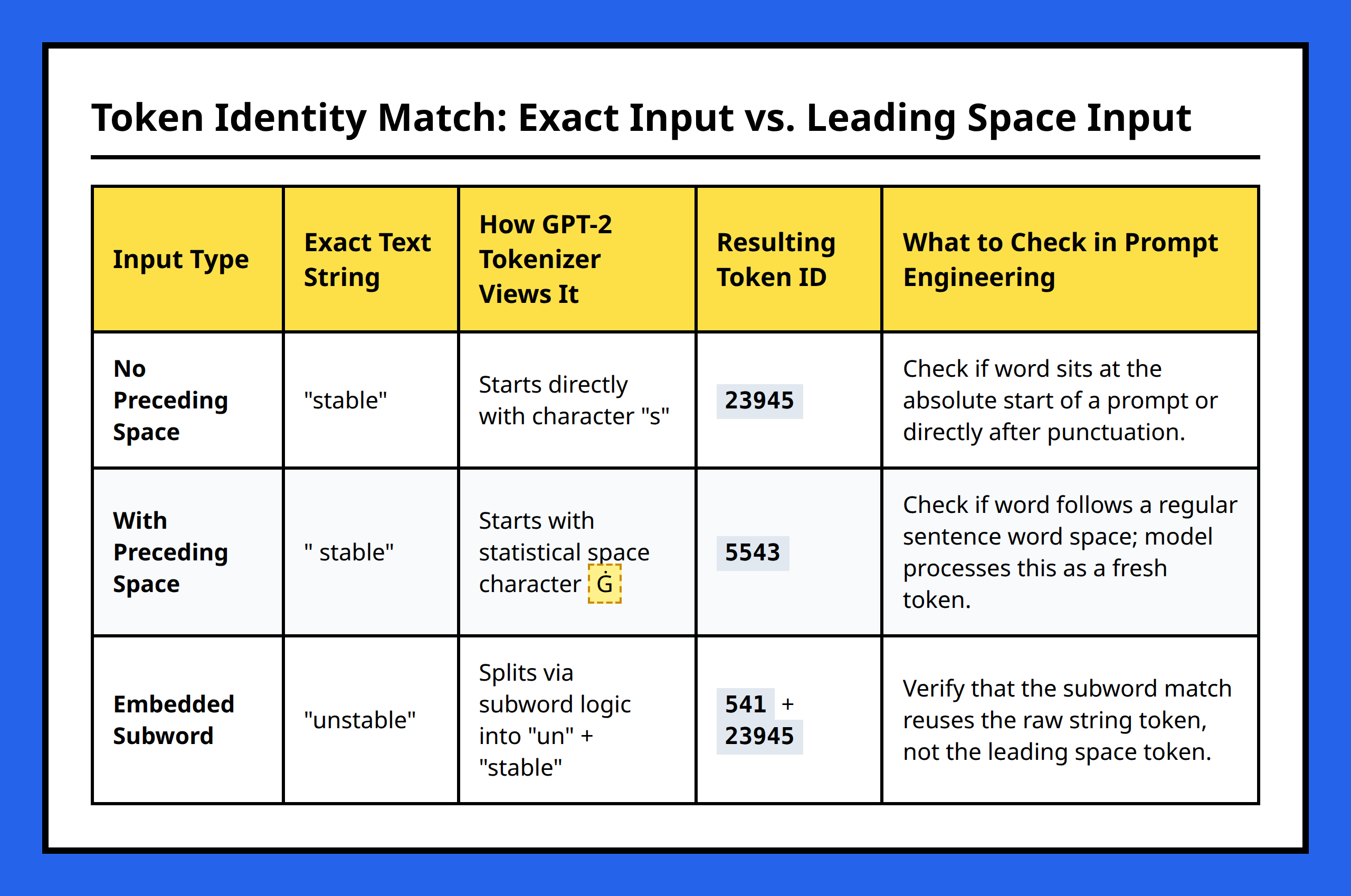
Consider “stable” and “ stable.” In GPT-2, the presence of a leading space changes the token identity:
"stable" → token without preceding space " stable" → token with preceding space This distinction helps the model understand where words begin in a sequence. A token with a leading space usually starts a word, whereas a token without a space often appears as a fragment inside another word.
Subword Reuse in Action

For example, the word “unstable” can reuse the fragment “stable” without a preceding space:

"unstable" → "un" + "stable" The tokenizer efficiently recombines familiar subwords, reducing the total number of tokens while preserving the meaning. This is why statistical segmentation relies on whitespace encoding as part of its compression strategy.
I find it fascinating how this mechanism allows the model to flexibly handle new or rare words. Instead of failing when it encounters an unseen word, the model can assemble it from known subword tokens, keeping context representation efficient.
Implications for Prompt Design

Understanding that whitespace is encoded in tokens changes how I approach prompt construction. Leading spaces are not cosmetic; they influence how the model interprets word boundaries and context. Omitting or adding a space can subtly change tokenization and, consequently, model outputs.
For prompt engineers, this means paying attention to spacing can improve the consistency and predictability of LLM responses. It also explains some unexpected token counts and alignment when analyzing sequences programmatically.
Why This Design Matters

In short, GPT-2’s treatment of leading spaces is not arbitrary. It reflects a carefully designed compromise between token efficiency, context representation, and subword reuse. By encoding spaces, the tokenizer maintains high compression for common patterns while still supporting flexible text assembly for rarer sequences.
Once I realized this, it became clear why “stable” and “ stable” are separate tokens: it’s a practical solution to statistical pattern learning, not a flaw. Recognizing this distinction helps me diagnose tokenization quirks and design more reliable prompts.
References:
- https://medium.com/@gaurlokesh1211/tokens-and-embeddings-the-foundation-of-language-models-a48bbdc89004
- https://discuss.huggingface.co/t/how-does-gpt-decide-to-stop-generating-sentences-without-eos-token/41623
- https://xcelore.com/gpt-2-to-gpt-oss-openais-transformer-evolution-explained/
- https://yannael.github.io/video2blogpost/final_output/blogpost.html
- https://stevekinney.com/courses/python-ai/tokenization
- https://blog.gopenai.com/diffusion-language-models-why-the-next-chatgpt-might-not-be-autoregressive-749161115dec
- https://ai.gopubby.com/how-llm-tokens-really-work-c8ffbbf94b69
- https://www.linkedin.com/pulse/copy-transformers-how-chatgpt-predicts-answers-our-questions-yadav-8jd8f
- https://arxiv.org/html/2605.01869v1
- https://computationalcreativity.net/iccc22/wp-content/uploads/2022/06/ICCC-2022_18L_Sawicki-et-al..pdf
- https://sararavi14.medium.com/gpt-2-architecture-demystified-a-step-by-step-breakdown-74b1c5c80d17
- https://en.wikipedia.org/wiki/GPT-2
- https://dev.to/nareshnishad/gpt-2-and-gpt-3-the-evolution-of-language-models-15bh









