
Counting characters, words, and GPT-style tokens across real books reveals something important: different tokenization methods expose completely different structural patterns in written language.
I used to think token counts were mostly a technical implementation detail. Then I started comparing the same books through multiple tokenization schemes, and the differences became hard to ignore. The numbers were not just measuring text length. They were exposing how language compresses, repeats, scales, and organizes itself.
Once you compare character counts, word counts, and GPT-style token counts side by side, tokenization starts looking less like preprocessing and more like a statistical lens on language itself.
Different Tokenizers See Different Versions of the Same Book
Imagine taking the same novel and measuring it three ways:
- total characters
- total words
- total GPT-2 tokens
The raw text does not change, but the structure you observe changes dramatically.
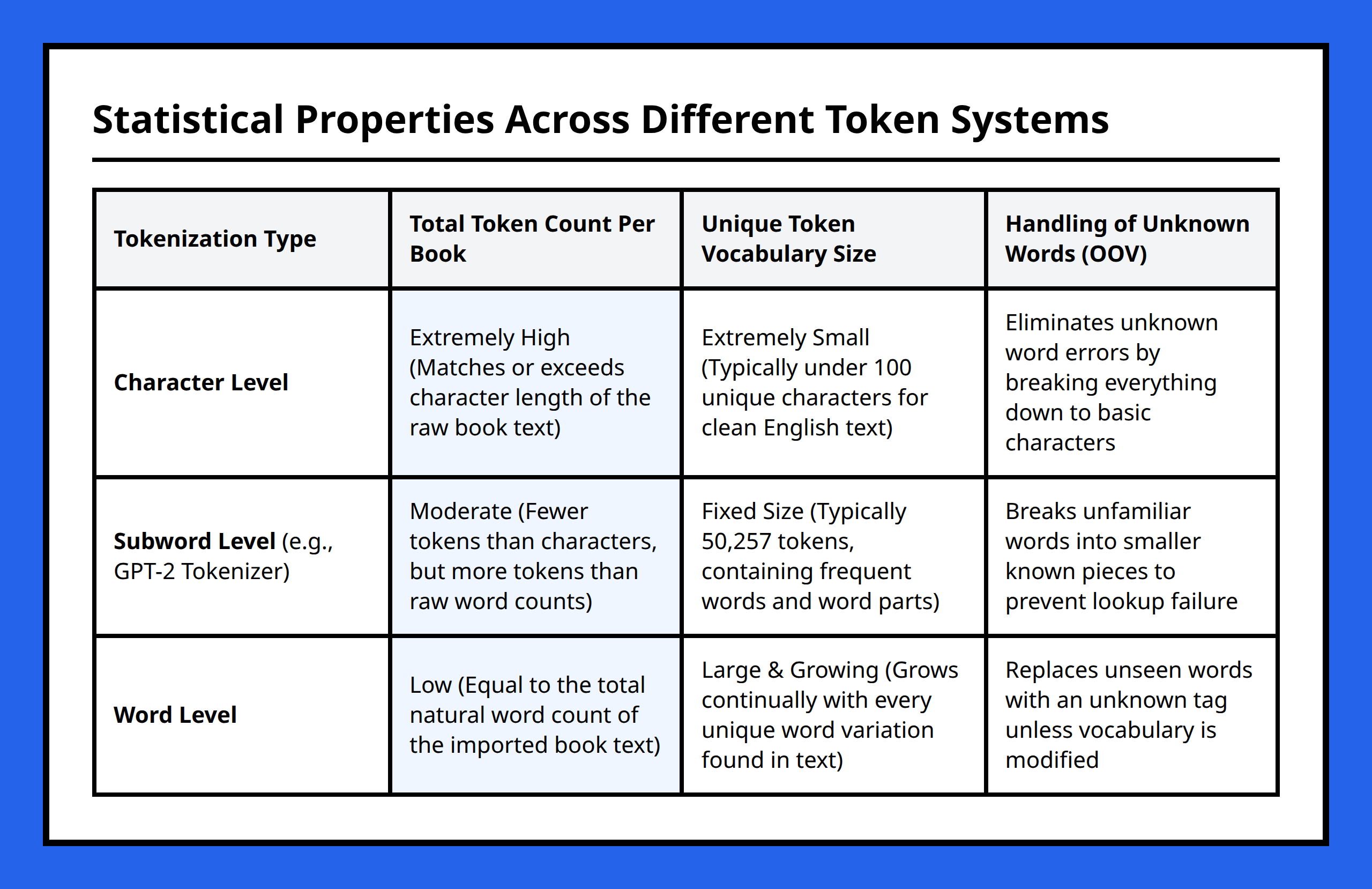
Character tokenization creates enormous sequences because every letter, space, and punctuation mark becomes its own unit. Word tokenization compresses aggressively because entire words become single units. GPT-style subword tokenization lands somewhere in the middle.
That middle position matters.
When books from Project Gutenberg were analyzed across these tokenization schemes, the results showed consistent scaling differences between characters, words, and GPT-style tokens. Books with hundreds of thousands of characters could compress into dramatically fewer GPT-style tokens because common word fragments and patterns were reused efficiently.
I find this especially interesting because the tokenizer is effectively learning which parts of language deserve to become reusable building blocks.
Character Counts Look Stable Until You Compare Vocabulary Diversity
One surprising result from the book-level analysis was how small the set of unique characters remained across many texts.
Most English books use roughly the same alphabet, punctuation, and spacing symbols. Even long novels often contain fewer than 100 unique characters. The total number of characters grows enormously, but the character vocabulary barely changes.
This creates an unusual scaling pattern:
- massive growth in total character count
- minimal growth in unique character count
At first glance, this makes written language appear statistically simple.
But that simplicity is misleading. Individual characters carry very little meaning. The letter “e” appears constantly, but its usefulness depends entirely on surrounding context.
I think this is why character-level tokenization feels inefficient for large language models. The vocabulary stays tiny, but the model must process huge sequences of low-information units before meaningful structure emerges.
Word Counts Expose a Different Kind of Complexity

Word tokenization changes the statistical picture immediately.
Total sequence length shrinks because entire words become single units, but vocabulary diversity explodes. Real books contain large numbers of unique words, including:
- rare names
- uncommon spellings
- verb variations
- specialized terms
- dialect differences
In the Gutenberg analysis, books with similar total word counts could still differ substantially in unique vocabulary size.
This creates a different scaling relationship:
- moderate growth in total words
- significant growth in unique vocabulary
A long fantasy novel, for example, might repeatedly introduce invented place names, titles, or character names. A technical book might contain domain-specific terminology that barely appears elsewhere. Word-level tokenization captures that diversity, but at a cost.
The vocabulary becomes difficult to manage efficiently.
I would be cautious about assuming larger vocabularies automatically mean richer language. Sometimes they simply reflect spelling variation, formatting differences, or rare word usage. That distinction matters when interpreting token statistics.
GPT-Style Tokens Compress Language Without Losing Flexibility
GPT-style tokenization revealed the most balanced statistical behavior in the analysis.
Instead of exploding vocabulary size like full-word tokenization, subword tokenization reused common fragments across many words. At the same time, it compressed sequences much more efficiently than character-level tokenization.
This produced a useful compromise:
- fewer total tokens than character systems
- smaller vocabularies than word systems
- better flexibility for handling rare or unseen text
I think this balance becomes easiest to understand when you imagine messy real-world text.
A customer support chat might include typos, usernames, product codes, emojis, and half-finished sentences in the same conversation. A rigid word-level system struggles because many of those exact words may never have appeared before. A character-level system can represent everything, but the sequences become extremely long.
Subword tokenization handles both pressures reasonably well.
That is exactly what the statistical comparisons across books were revealing: GPT-style tokenization scales differently because it compresses recurring language patterns instead of treating every word as fully unique.
The Relationship Between Total Tokens and Unique Tokens Matters

One of the most useful parts of the analysis was comparing total counts against unique counts.
The relationship tells you something important about repetition and structure in language.
Books with more total tokens generally had more unique tokens, but the relationship differed depending on the tokenizer.
Character vocabularies barely expanded.
Word vocabularies expanded aggressively.
GPT-style token vocabularies expanded more gradually because many new words could be assembled from existing subword pieces.
I see this as one of the clearest demonstrations that tokenization is not just encoding text. It is choosing which statistical regularities deserve to become reusable components.
That choice changes how language scales computationally.
Outliers Reveal Things the Averages Hide
The book analysis also exposed an important visualization lesson.
One collection of Edgar Allan Poe writings appeared as an outlier because it contained additional stylized characters like accented letters and unusual symbols. The difference was numerically small, but it stood out sharply because the rest of the books were so statistically similar at the character level.
I like examples like this because they show how token statistics can expose hidden properties of a dataset that ordinary reading would barely notice.
A tokenizer is sensitive to details humans often ignore:
- formatting quirks
- punctuation habits
- special characters
- repeated subword patterns
- language-specific compression behavior
That sensitivity is part of why tokenization matters so much for language models.
Token Counts Quietly Shape How Language Models See Text
After looking at these book-level comparisons, I stopped thinking about tokenization as a neutral translation layer.
Different tokenization schemes impose different statistical assumptions about language. Character tokenization assumes language should be decomposed into minimal units. Word tokenization assumes whole words are the primary meaningful units. GPT-style tokenization assumes recurring fragments and patterns are the most useful compromise.
The empirical comparisons across real books make those assumptions visible.
And once you see how differently the same text behaves under different token systems, it becomes much harder to treat tokenization as a minor preprocessing step.
References:
- https://plato.stanford.edu/archives/fall2016/entries/types-tokens/
- https://herculeaf.wordpress.com/2019/05/04/type-token-ratio/
- https://languagelog.ldc.upenn.edu/nll/
- https://onlinelibrary.wiley.com/doi/10.1002/9781119839859.ch5
- https://medium.com/data-science/all-languages-are-not-created-tokenized-equal-cd87694a97c1
- https://www.researchgate.net/post/Are_there_other_measures_apart_from_Type_Token_ratio_to_evaluate_the_complexity_of_different_texts
- https://arxiv.org/html/2502.14969v2
- https://pmc.ncbi.nlm.nih.gov/articles/PMC4567506/
- https://www.sciencedirect.com/science/article/pii/S1364661325002797
- https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00747/128941/How-Much-Semantic-Information-is-Available-in
- https://archive.carla.umn.edu/learnerlanguage/spn/comp/activity4.html
- https://quantumdesignteam.medium.com/how-language-shapes-our-reality-cf7401218db2









