
Understanding large language models isn’t about reading weights; it’s about analyzing emergent patterns across vast high-dimensional spaces, where behavior arises from complex interactions rather than simple step-by-step rules.
When I first started studying LLMs, I assumed that having full access to model weights would be enough to understand their decisions. That intuition was quickly challenged. Even with the weights in hand, the sheer dimensionality and interconnections make it impossible to interpret the model as if it were a traditional algorithm.
Mechanistic interpretability reframes the problem: instead of trying to “read” an LLM like code, it treats the model as a high-dimensional system where patterns emerge from the collective interaction of millions or billions of parameters .
The Black Box Problem and Why Weights Aren’t Enough

One of the most common misconceptions is that open-source weights equal transparency. In reality, weights are just numbers—overwhelmingly many numbers—without context. The challenge isn’t knowing the exact values but understanding how they interact to produce coherent behavior. It’s similar to having a movie compressed into pixels and trying to infer the plot by examining each pixel individually. Without a framework for interpretation, the details alone are meaningless .
Emergent Behavior in High-Dimensional Spaces
LLMs exhibit behavior that isn’t explicitly programmed but emerges from complex interactions among neurons and layers. I think about this as akin to observing patterns in a crowd: you cannot predict every individual movement, yet global behaviors appear. Similarly, LLMs generate coherent language, recognize patterns, and perform tasks not because each weight is coded for a specific function, but because high-dimensional interactions produce emergent capabilities .
Why We Need Mechanistic Interpretability
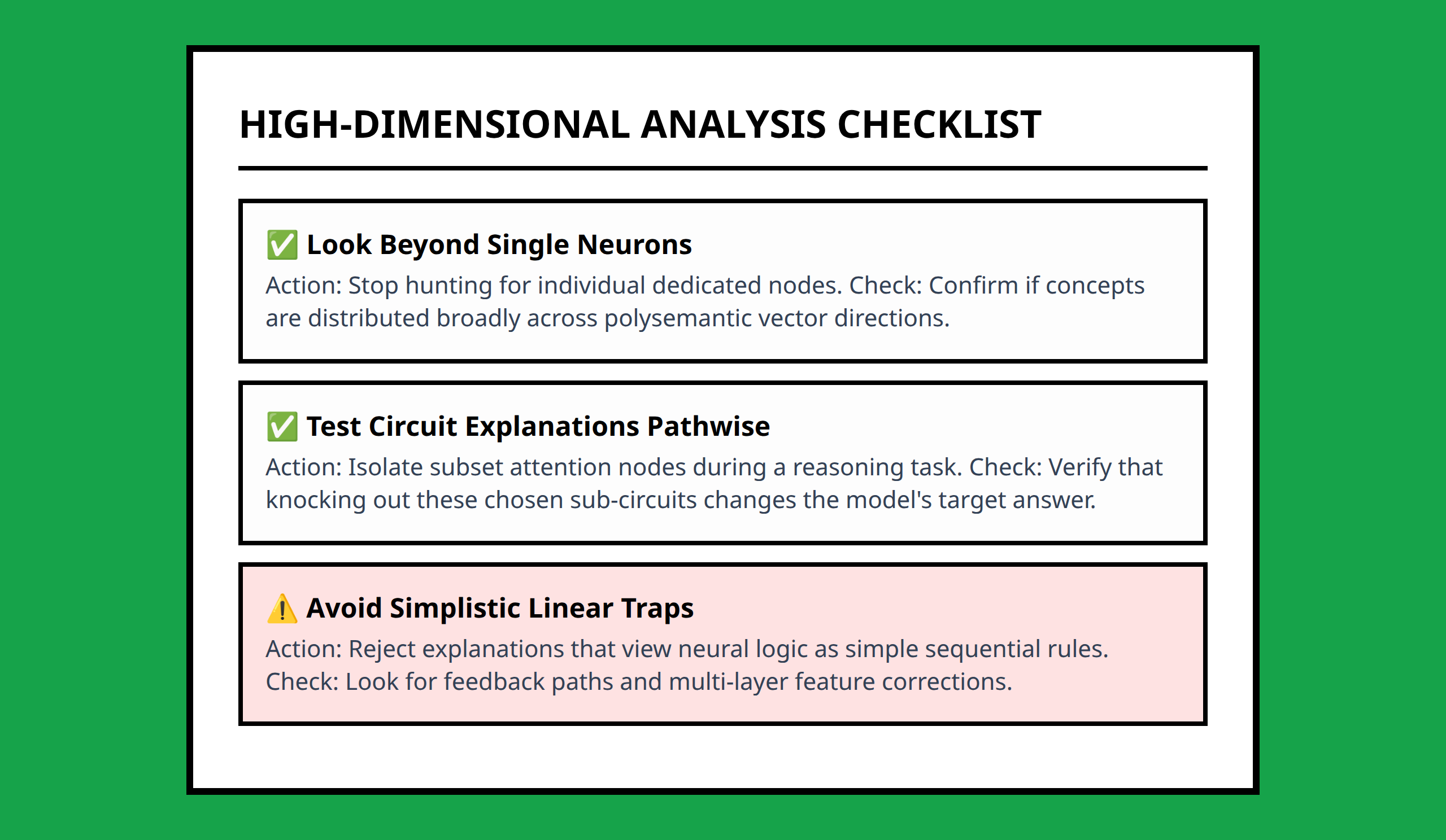
Mechanistic interpretability aims to discover the internal structures and interactions that lead to specific outputs. It’s less about transparency slogans and more about systematic analysis. By studying patterns across high-dimensional spaces, we can begin to identify circuits, motifs, or neuron combinations that reliably contribute to certain behaviors. I find this approach far more practical than trying to trace outputs directly to individual weights, which would be like trying to reconstruct a novel from a handful of letters .
Comparing LLM Analysis to Movie Interpretation

One analogy that resonates with me is watching a film pixel by pixel. You see every individual pixel, but the story remains invisible. Similarly, inspecting LLM weights provides exhaustive numerical detail, yet the emergent behavior—language understanding, reasoning, or reasoning errors—cannot be inferred directly. Mechanistic interpretability allows us to step back, identify patterns, and start mapping how clusters of neurons and activations drive coherent outputs .
Practical Takeaway for Researchers and Engineers

The key insight is that interpretability requires moving beyond raw weights. It’s about understanding LLMs as complex systems and designing experiments, visualizations, and analytical tools that reveal emergent patterns. Recognizing high-dimensional interactions helps explain why even open-source models remain “black boxes” without targeted investigation. For anyone developing or analyzing LLMs, focusing on emergent behavior rather than individual weights is crucial for meaningful mechanistic understanding .
References:
- https://intuitionlabs.ai/articles/mechanistic-interpretability-ai-llms
- https://medium.com/@zzhang_29583/why-llms-can-explain-algorithms-they-cannot-execute-46d60d0546c2
- https://www.reddit.com/r/singularity/comments/1h0slzl/mechanistic_interpretability_and_how_it_might/
- https://arxiv.org/html/2602.11180v1
- https://medium.com/@adnanmasood/inside-the-black-box-a-practical-field-guide-to-mechanistic-interpretability-b8757600e2de
- https://dl.acm.org/doi/10.1145/3787104
- https://www.neelnanda.io/mechanistic-interpretability/glossary
- https://leonardbereska.github.io/blog/2024/mechinterpreview/
- https://towardsdatascience.com/mechanistic-interpretability-peeking-inside-an-llm/
- https://arxiv.org/html/2507.08017v4









