
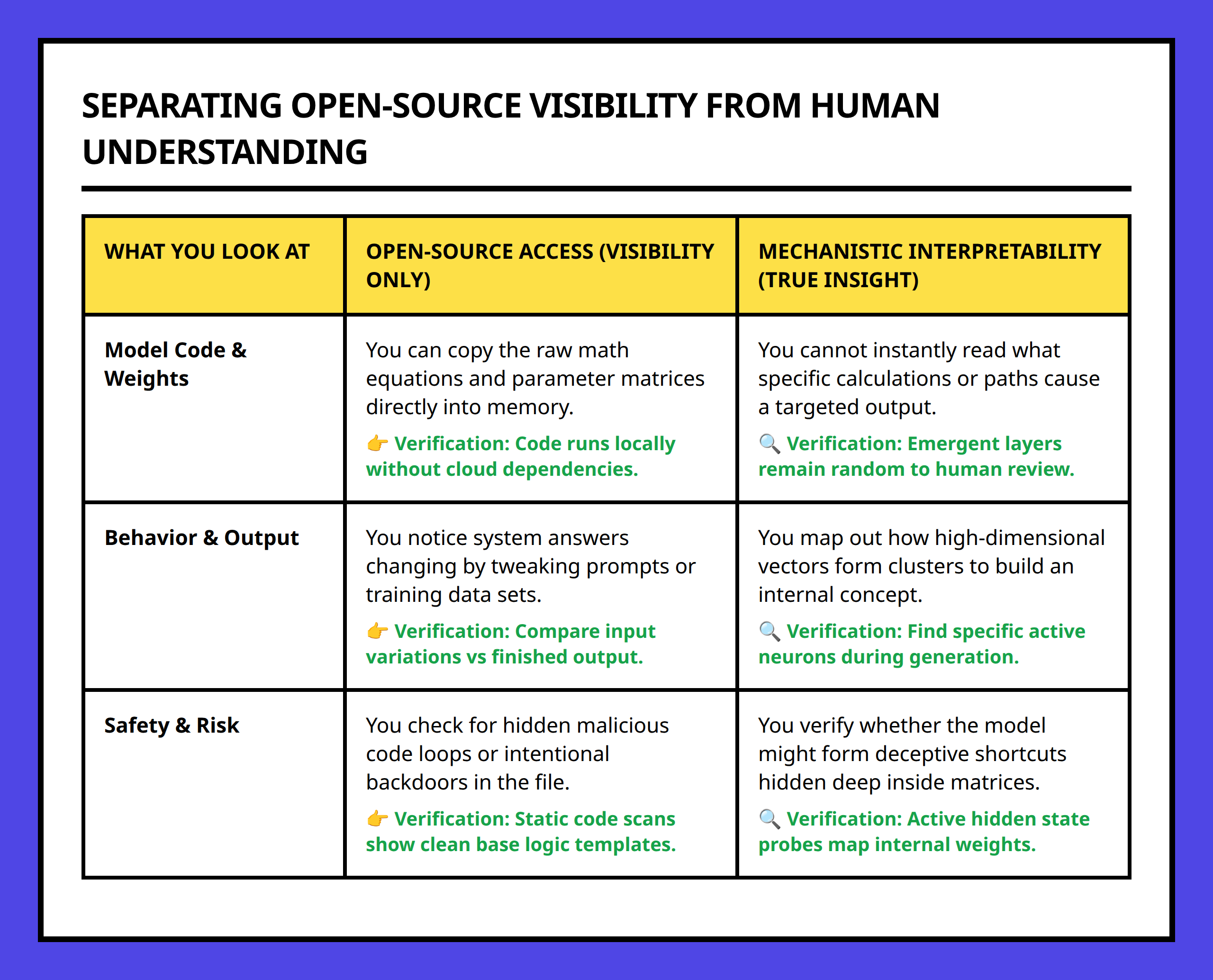
Open-source LLMs may expose their code and weights, but that does not automatically make their behavior understandable. The real challenge is not access. It is emergent complexity inside high-dimensional systems.
When people first hear that a language model is open source, they often assume the transparency problem has been solved. The reasoning feels intuitive: if researchers can inspect the code and weights directly, then the model should no longer behave like a black box.
I used to partially believe that myself. But the deeper I looked into mechanistic interpretability, the clearer it became that visibility and understanding are not the same thing.
Open Weights Solve a Different Problem
Open-source models absolutely improve transparency in some important ways.
Researchers can inspect:
- the architecture
- training procedures
- parameter values
- datasets when available
- evaluation methods
That matters because proprietary systems can hide dangerous assumptions, hidden limitations, or biased design choices behind closed APIs.
But interpretability is a different challenge entirely.
I think this distinction gets blurred constantly in public discussions. People treat “hidden from the public” and “difficult to understand” as if they are the same problem. They are not.
A locked safe and a massive tangled machine are difficult for completely different reasons.
The Difficulty Comes From Emergent Interactions

The core problem is that modern LLM behavior emerges from interactions across enormous numbers of parameters operating simultaneously.
Even if every weight is publicly visible, the system still contains:
- millions or billions of interacting components
- distributed representations
- high-dimensional activation spaces
- emergent internal patterns
- non-obvious feature interactions
No human can simply “read” those weights line by line and infer the model’s reasoning process.
I sometimes compare this to staring at the pixel values of a movie frame-by-frame and expecting to understand the story. The information is technically visible, but the meaningful structure only emerges at a much higher level of organization.
That is why open access alone does not produce human understanding.
Why Equations Do Not Automatically Create Understanding

One surprising lesson in interpretability research is that exact mathematical definitions are often insufficient for intuitive understanding.
LLMs are built from operations researchers can fully describe mathematically:
- matrix multiplications
- attention mechanisms
- activation functions
- gradient optimization
But describing the equations is not the same as understanding the emergent behavior they collectively produce.
A realistic example helps here.
Imagine someone hands you the full electrical diagram for a modern city. Every wire, circuit, transformer, and connection is perfectly documented. That does not mean you instantly understand traffic patterns, economic activity, or daily human behavior across the city.
The lower-level rules are visible. The higher-level system behavior remains difficult.
I think LLMs create the same kind of interpretability gap.
Distributed Representations Make Human Intuition Struggle
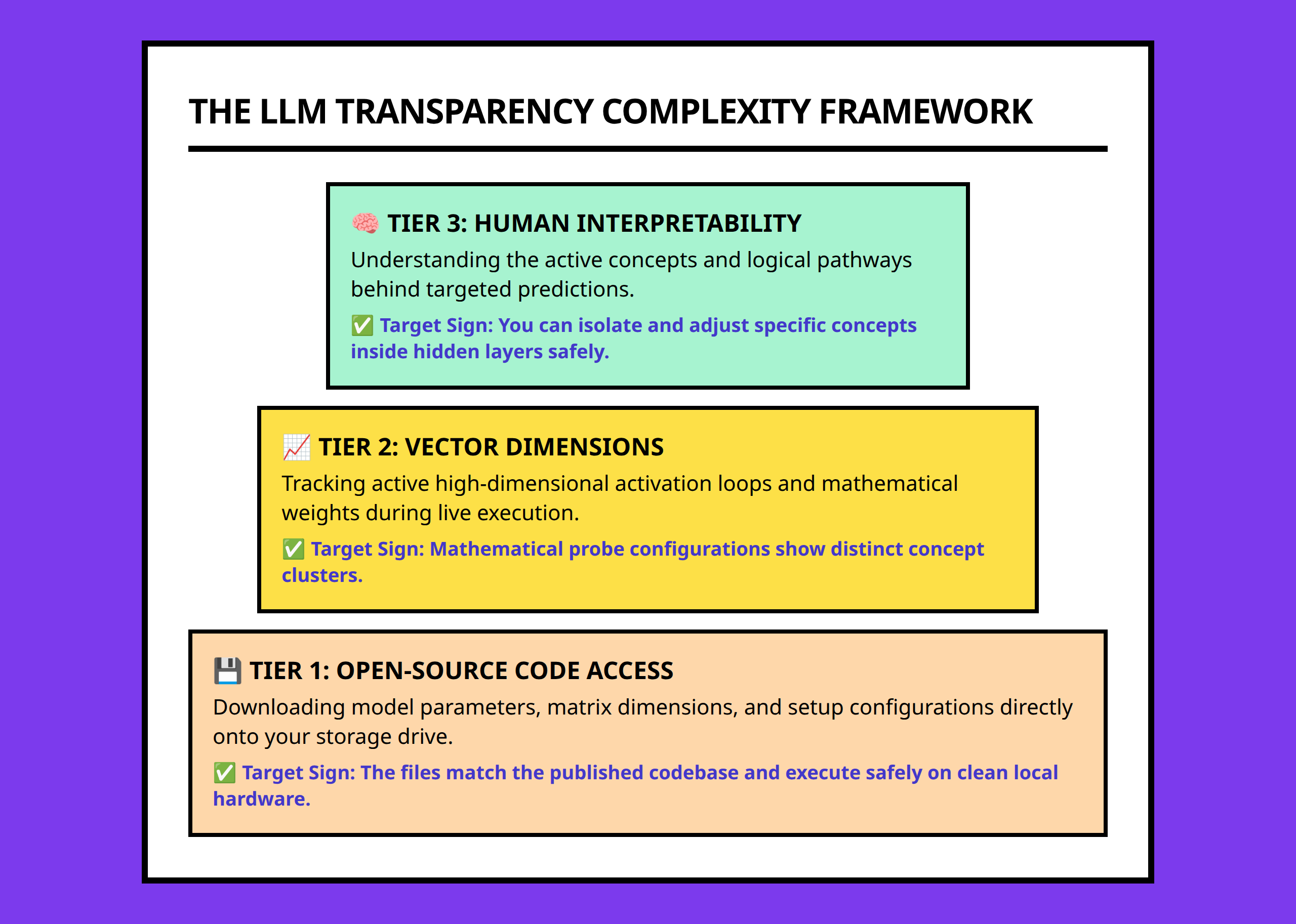
Part of the difficulty comes from how language models store information.
Traditional software often contains relatively localized logic:
- this function handles passwords
- this module processes payments
- this rule checks dates
LLMs do not organize themselves that cleanly.
Representations are distributed across large numbers of neurons and layers. A concept may not exist in one location. It may emerge from coordinated activity patterns spread across the network.
I would be cautious about assuming there is always a neat “reasoning neuron” or isolated “truth module” hidden somewhere inside the model.
Interpretability becomes difficult precisely because meaningful behavior is distributed rather than localized.
The Black Box Feeling Persists Even With Full Access

This is why many open-source researchers still describe LLMs as black boxes despite having unrestricted model access.
The phrase does not necessarily mean:
“We are forbidden from seeing the internals.”
Often it means:
“The internals are too complex to translate directly into human understanding.”
I think that is an important conceptual shift.
The interpretability problem is not just a transparency problem. It is a systems-analysis problem.
A researcher can inspect every parameter and still struggle to explain:
- why a hallucination occurred
- why certain reasoning patterns emerge
- why jailbreak prompts work
- why representations organize the way they do
The challenge comes from complexity, not secrecy alone.
Why This Matters for AI Discussions
I notice a recurring mistake in debates around AI safety and open-source models.
People sometimes frame the conversation as if releasing weights automatically creates accountability and interpretability. Open access certainly improves external scrutiny, but it does not magically convert neural networks into human-readable systems.
That distinction matters because it changes what researchers should focus on.
If the problem were merely hidden access, publishing weights would largely solve it.
But if the problem is emergent high-dimensional complexity, then interpretability requires:
- new analytical tools
- representation analysis
- mechanistic experiments
- behavioral probing
- system-level investigation
Open-source access helps those efforts, but it does not replace them.
The Most Important Misconception to Avoid
The biggest misconception, in my view, is imagining that understanding naturally follows visibility.
It often does not.
A microscope gives scientists access to cells, but it does not automatically explain biology. A telescope exposes distant galaxies, but interpretation still requires theories, models, and years of analysis.
Open-source LLMs create the same situation.
The systems become visible. The deeper challenge is still learning how to interpret behavior emerging from networks so large and interconnected that the meaningful structure hides inside the interactions themselves.
References:
- https://www.reddit.com/r/OpenAI/comments/1d6vucu/why_open_source_ai_is_not_really_open_source_and/
- https://www.youtube.com/watch?v=VjR4JbB6lMs
- https://www.reddit.com/r/singularity/comments/1d6vt24/why_open_source_ai_is_not_really_open_source_and/
- https://www.reddit.com/r/aipromptprogramming/comments/1lvafmk/if_llms_dont_understand_why_are_they_so_good_at/
- https://www.reddit.com/r/aipromptprogramming/comments/1lvafmk/if_llms_dont_understand_why_are_they_so_good_at/n24l1i0/
- https://www.reddit.com/r/aipromptprogramming/comments/1lvafmk/if_llms_dont_understand_why_are_they_so_good_at/n24p1br/
- https://community.openai.com/t/biggest-problem-with-llms-llms-dont-know-anything-about-how-they-themselves-are-built/1113807
- https://www.quora.com/Why-are-open-source-projects-hard-to-understand
- https://www.reddit.com/r/ChatGPTCoding/comments/1ip7yhf/llms_are_fundamentally_incapable_of_doing/
- https://www.reddit.com/r/LocalLLaMA/comments/19a7mlx/local_llm_open_source_so_why_do_influencers_use/
- https://medium.com/@aksharabalan0704/the-ai-illusion-why-llms-dont-really-understand-language-45b9474d8f51
- https://andrewzuo.com/llms-and-the-decline-of-open-source-24f5cf419dee
- https://arxiv.org/html/2409.16559v1
- https://www.quantamagazine.org/why-language-models-are-so-hard-to-understand-20250430/
- https://www.bakedwith.com/en/blog/open-source-llms-vs-closed-source-llms
- https://news.ycombinator.com/item
- https://pub.towardsai.net/llm-weaknesses-101-b8943d8f94fa
- https://www.reddit.com/r/aipromptprogramming/comments/1lvafmk/if_llms_dont_understand_why_are_they_so_good_at/n24mslq/
- https://arxiv.org/abs/2510.20941









