
Tokenization isn’t just a preprocessing step—it directly impacts how much meaningful text a large language model can handle and how efficiently it uses compute resources.
I first realized the impact of tokenization when I experimented with different text inputs in GPT-style models. It was surprising how much the number of tokens affected both the model’s context span and performance, even before any of the “intelligence” kicked in.
The core idea is simple: a model sees sequences of numbers, not letters or words. How you break text into tokens determines how much content fits into a fixed context window.

Token Count Is a Measure of Compression
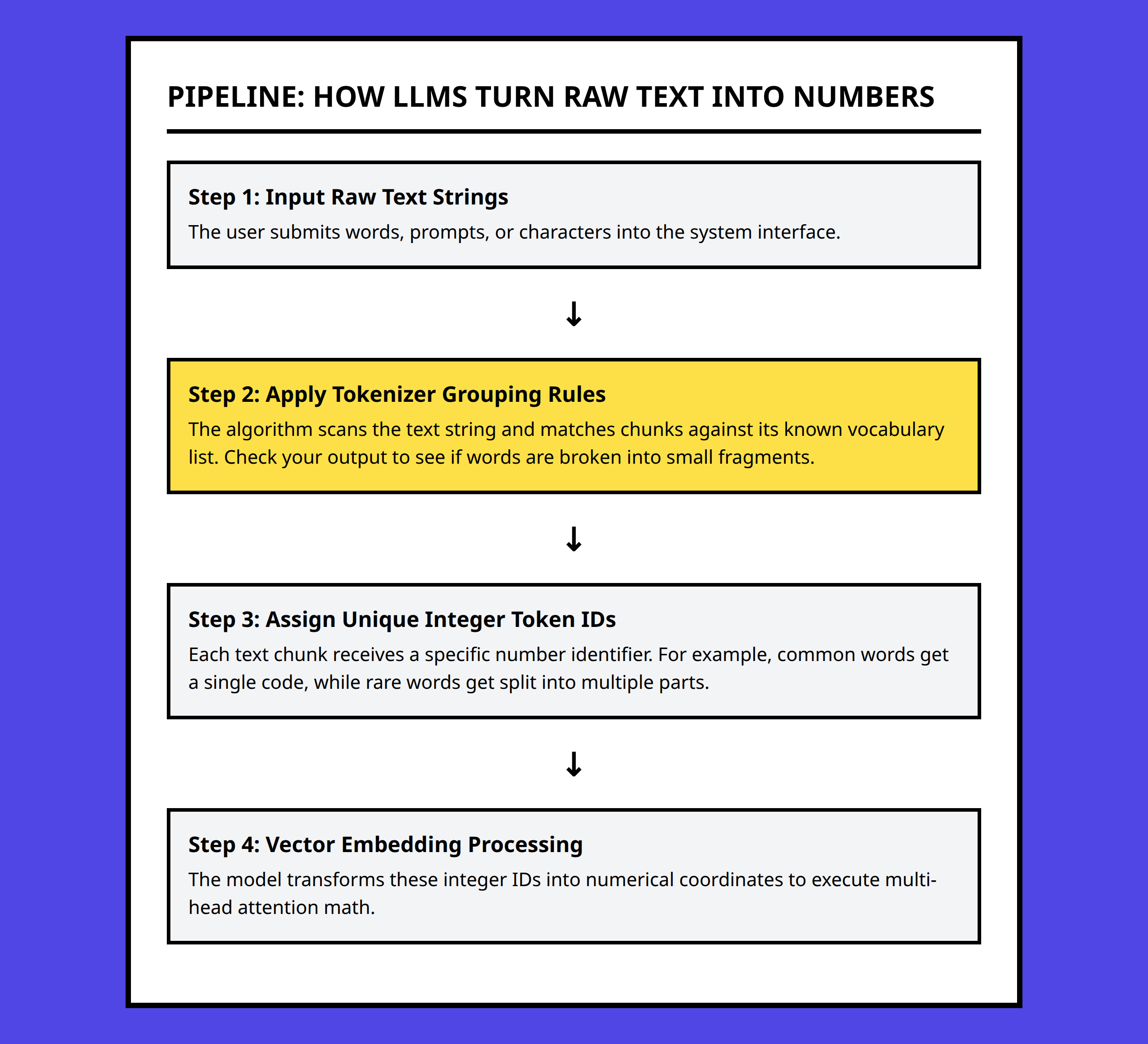
Consider the word “hello.” At the character level, it’s five tokens: h, e, l, l, o. As a single token in a subword tokenizer, it may compress to one token. The difference seems trivial for one word, but it scales quickly.
I like to think of tokenization as compression: the more efficiently text is encoded, the more information the model can process at once. Character-level tokenization is flexible but inefficient. Word-level tokenization is efficient for common words but brittle for rare terms. Subword tokenization balances these tradeoffs, allowing frequent sequences to compress while still handling rare or new words.
This compression directly affects context windows. A model has a fixed token limit. Fewer tokens per meaning unit mean longer effective context. More tokens per meaning unit consume the window faster, clipping earlier parts of the text.
Why Context Windows Matter
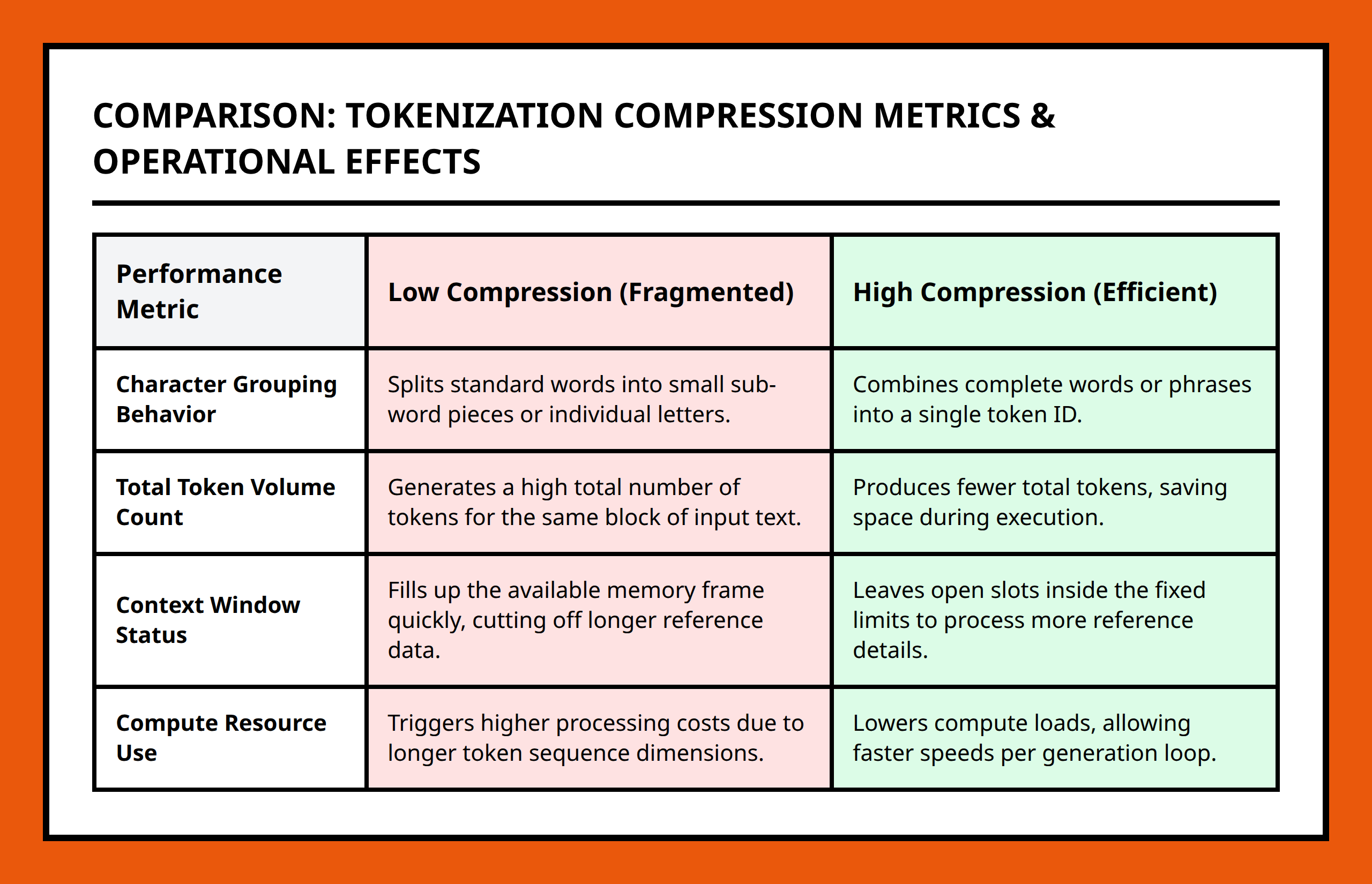
Context windows define how much the model “remembers” when generating text. If the tokenization is inefficient, earlier parts of a conversation or document may be truncated prematurely.
I noticed this effect during long-form content generation. Text tokenized inefficiently meant the model lost reference to its own earlier paragraphs. Conversations and multi-step reasoning became less coherent. Efficient tokenization keeps more relevant content in memory, improving performance without changing the model’s architecture.
Token Efficiency and Compute Costs

Tokenization also has financial and computational implications. Each token processed costs compute cycles. Fewer tokens for the same semantic content reduce memory usage and speed up processing.
For example, compressing repetitive patterns into single subword tokens reduces the total sequence length. That means the same GPU can process longer passages, or a model can generate text faster for the same cost.
I often think of it like packing luggage. A well-compressed suitcase carries more essentials without exceeding airline limits. Similarly, a well-tokenized input carries more meaningful content within the model’s fixed token window.
Choosing the Right Tokenization Strategy

The key takeaway is that tokenization isn’t arbitrary. Developers and prompt engineers need to consider how token choice affects model efficiency, context retention, and computation. Even small differences in compression strategy can scale up to large effects on performance and cost in production systems.
When I analyze tokenization strategies, I look for the balance between compression, flexibility, and real-world text handling. Subword methods, like those used in GPT-2, typically hit the sweet spot, compressing frequent sequences while still allowing for new or rare words to be tokenized effectively.
Understanding tokenization is the first step toward optimizing LLM applications. Efficient token usage leads to better context coverage, lower compute costs, and ultimately, more coherent and reliable model output.
References:
- https://medium.com/@anicomanesh/token-efficiency-and-compression-techniques-in-large-language-models-navigating-context-length-05a61283412b
- https://arxiv.org/html/2511.03825v1
- https://www.linkedin.com/pulse/token-efficiency-age-llms-languages-compression-art-saying-mark-jones-eubee
- https://shieldbase.ai/blog/understanding-tokenization-efficiency-and-tradeoffs-for-llms
- https://www.kern-it.be/en/definitions/token/
- https://openreview.net/forum
- https://www.sitepoint.com/optimizing-token-usage-context-compression-techniques/
- https://www.linkedin.com/posts/tlberglund_your-llms-context-window-is-a-precious-resource-activity-7427101731890737153-ZzFX
- https://natesnewsletter.substack.com/p/context-windows-are-a-lie-the-myth
- https://www.diva-portal.org/smash/get/diva2:1886192/FULLTEXT01.pdf
- https://nebius.com/blog/posts/how-tokenizers-work-in-ai-models
- https://www.traceloop.com/blog/a-comprehensive-guide-to-tokenizing-text-for-llms
- https://redis.io/blog/context-rot/
- https://criticalmynd.medium.com/understanding-llm-token-counts-what-1-000-128-000-and-1-million-tokens-actually-mean-9751131ac197









