
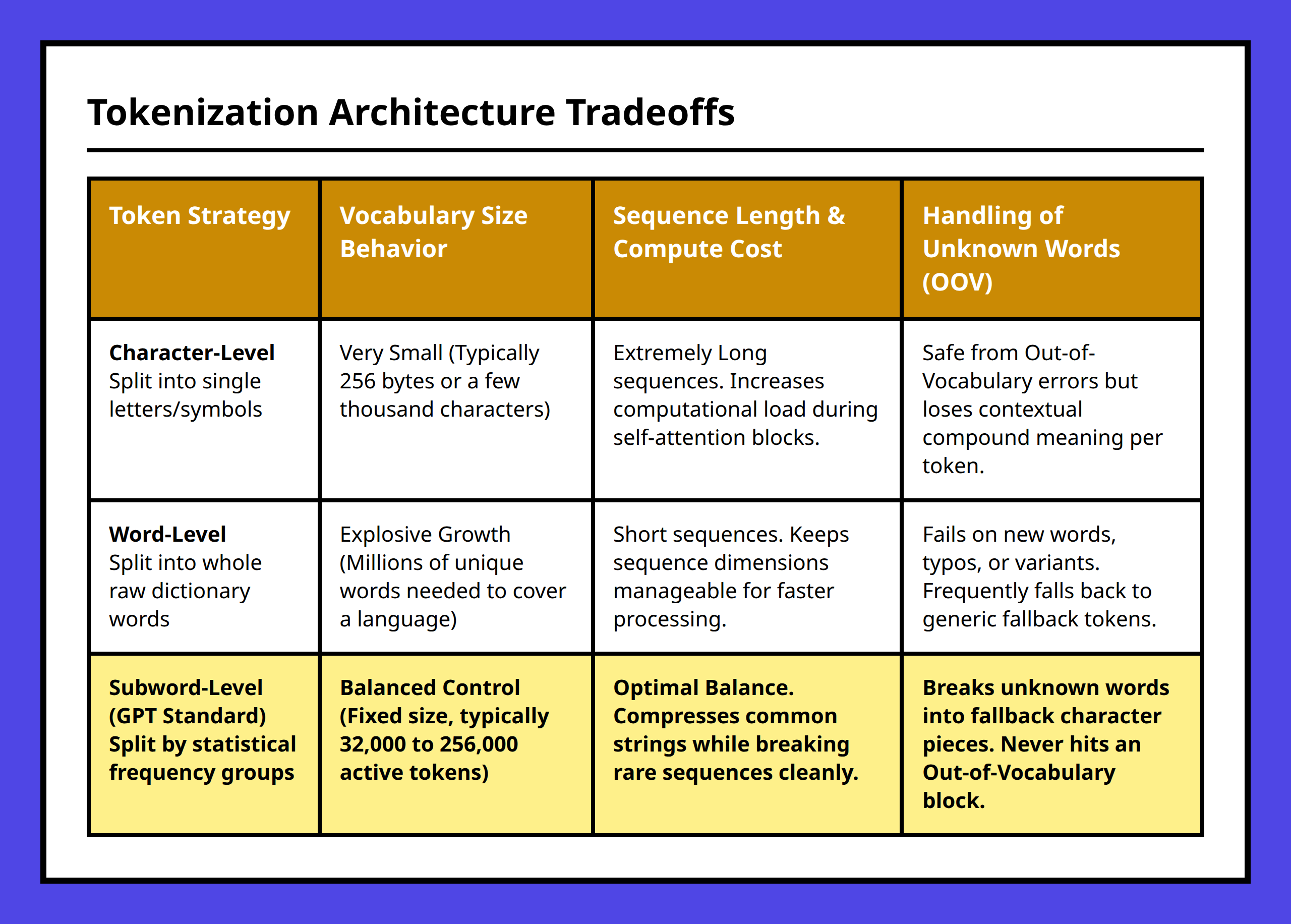
GPT-style tokenization works because it avoids two expensive extremes: character-level systems that waste context space and word-level systems that explode vocabulary size. Subword tokenization sits in the middle and turns out to be a surprisingly practical compromise.
One of the easiest mistakes to make when learning about language models is assuming that text enters the model more or less the way humans read it. It doesn’t. Before an LLM sees anything, the text has already been chopped into numeric pieces called tokens.
I used to think tokenization was mostly a preprocessing detail. The more I looked at how modern tokenizers behave, the more it became clear that tokenization quietly shapes almost everything downstream: context length, memory efficiency, vocabulary size, and even how flexible the model can be with messy real-world text.
The interesting part is that modern systems like GPT-2 did not settle on words or characters. They landed somewhere in between.
Character Tokenization Looks Simple Until You Try to Scale It
The most straightforward tokenizer is a character tokenizer. Every letter, punctuation mark, and space becomes its own token.
If you tokenize the word “hello” at the character level, you get five separate pieces:
h → token e → token l → token l → token o → token At first glance, this feels elegant. The vocabulary stays tiny. English only needs letters, digits, punctuation, and some symbols. That simplicity is attractive.
But the compression efficiency is terrible.
A language model processes sequences of tokens, not sequences of words. If every character becomes its own token, the context window fills up extremely fast. A short sentence suddenly becomes dozens of tokens. A long article becomes thousands.
This creates a practical bottleneck. Imagine two systems with the same context limit:
- One stores text character by character
- The other stores common words or subwords
The second system can fit dramatically more meaning into the same space.
I think this is the point many beginners miss. Tokenization is not just about converting text into numbers. It is also a compression strategy.
A customer support chatbot is a good example. If the tokenizer wastes space on individual characters, the model runs out of room faster during a long conversation. Earlier context gets clipped sooner. Replies become less coherent because the model literally cannot “remember” enough prior text inside its fixed token budget.
Character tokenization also creates another problem: low information density.
A single character carries very little meaning on its own. The letter “a” appears almost everywhere. The model has to combine huge numbers of low-value units before meaningful structure starts emerging.
Word Tokenization Fixes One Problem and Creates Another

The obvious reaction is to move up from characters to full words.
Now “hello” becomes one token instead of five. Compression improves immediately. Context windows become more useful because the model can process larger chunks of meaning at once.
But word tokenization introduces a different scaling problem: vocabulary explosion.
Human language is messy. A realistic tokenizer would need:
- common words
- rare words
- misspellings
- plural forms
- verb tenses
- technical jargon
- programming syntax
- slang
- emoji variations
- multiple languages
The vocabulary size grows rapidly.
This becomes expensive because every token needs an index inside the model vocabulary. The larger the vocabulary, the more parameters and infrastructure the model needs to manage.
There is also a flexibility problem.
Suppose a tokenizer has never seen a newly invented product name, a rare medical term, or an unusual username. A pure word-level system struggles because the entire word is missing from the vocabulary.
I often picture this happening in normal workplace situations. Someone pastes an internal project codename, a strange URL, or a typo-filled support ticket into an AI assistant. Real-world text is full of irregular fragments. A rigid word-based tokenizer handles that badly.
Character tokenization is flexible but inefficient. Word tokenization is efficient but rigid.
That tension is exactly why subword tokenization became the standard.
Subword Tokenization Solves the Tradeoff

Modern GPT-style tokenizers use subwords.
Instead of treating language as either pure characters or pure words, the tokenizer learns reusable text fragments that appear frequently together.
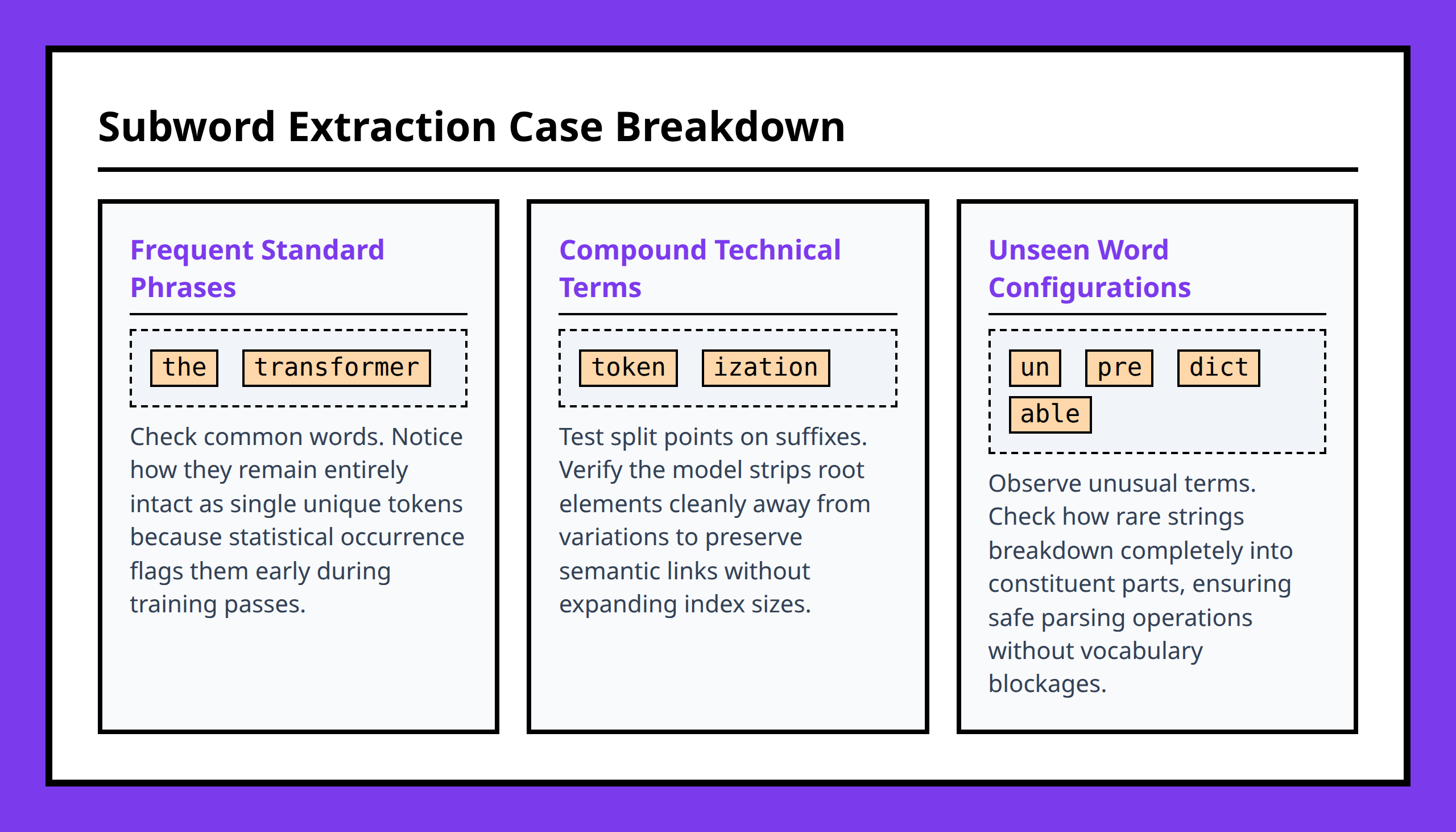
For common English words, the tokenizer may store the entire word as one token:
"hello" → one token But less common words can be broken into smaller pieces:
"unbelievable" → "un" + "believ" + "able" This turns out to be an extremely practical compromise.
Common patterns compress efficiently because frequent words and fragments become reusable units. Rare or unfamiliar text can still be assembled from smaller pieces instead of failing completely.
That flexibility matters more than it first appears.
A tokenizer trained on internet-scale text eventually notices that certain character combinations appear constantly:
- “th”
- “ing”
- “tion”
- “pre”
- “able”
Those fragments become useful building blocks.
Meanwhile, strange or brand-new words can still be decomposed into recognizable subparts instead of becoming unknown tokens.
Why GPT Tokenizers Care About Spaces More Than Humans Do
One subtle detail in GPT-style tokenization surprised me the first time I saw it.
The tokenizer often treats leading spaces as part of the token itself.
For example:
" stable" ≠ "stable" Those become different tokens.
At first this feels unnecessary because humans mentally ignore the distinction. But statistically, the distinction matters.
The version with a leading space usually appears as a standalone word. The version without a leading space may appear inside another word.
For example:
"unstable" may reuse the token for:
"stable" without the preceding space.
This is one of the clearest signs that GPT tokenization is driven by statistical efficiency, not human grammar rules.
I think this is an important mindset shift. The tokenizer is not trying to understand language the way a linguist would. It is trying to segment text into reusable chunks that compress well and appear frequently in real data.
Byte-Pair Encoding Is Basically a Frequency Game
The core mechanism behind GPT-2 tokenization is byte-pair encoding, usually shortened to BPE.
The idea is surprisingly mechanical.
The tokenizer starts small, often at the character level. Then it repeatedly merges character pairs that appear together frequently.
If “th” appears constantly, it becomes a reusable token.
If “ing” appears constantly, it becomes another token.
Over time, larger and larger patterns form.
The important detail is that the tokenizer is not manually programmed with language rules. It learns statistically useful fragments from large text datasets.
I like this approach because it explains why tokenizers handle messy internet language reasonably well. Internet text is inconsistent, typo-heavy, multilingual, and full of weird formatting. A purely handcrafted linguistic system would struggle to keep up.
A statistical tokenizer adapts more naturally because it only cares whether patterns appear frequently enough to deserve compression.
Why Subword Tokenization Became the Practical Standard

The more I study tokenizer design, the less it looks like a purely linguistic problem and the more it looks like an engineering compromise.
Good tokenization has to balance several competing pressures at once:
- compression efficiency
- context window usage
- vocabulary size
- memory cost
- flexibility with rare text
- support for multiple languages and formats
Character systems fail on efficiency.
Word systems fail on flexibility and vocabulary scale.
Subword systems are imperfect, but they distribute the tradeoffs in a way that works well enough at internet scale.
That “good enough” balance is probably the real reason they became dominant.
Whenever I see people describe tokenization as a minor preprocessing step, I think they underestimate how much pressure is concentrated into this one design choice. The tokenizer quietly decides how language gets compressed before the model ever begins reasoning about it.
And once you notice that, modern LLM architecture starts looking a little less magical and a lot more like careful constraint management.
References:
- https://medium.com/data-science/word-subword-and-character-based-tokenization-know-the-difference-ea0976b64e17
- https://www.reddit.com/r/OpenAI/comments/1erxgx1/gpts_understanding_of_its_tokenization/
- https://www.reddit.com/r/MachineLearning/comments/uukxk7/d_characterlevel_vs_wordlevel_tokenization/
- https://seantrott.substack.com/p/tokenization-in-large-language-models
- https://www.youtube.com/watch?v=zjoauP3MhM8
- https://nebius.com/blog/posts/how-tokenizers-work-in-ai-models
- https://www.ai21.com/knowledge/tokenization/
- https://www.newline.co/@zaoyang/trade-offs-in-subword-tokenization-strategies–be3e6abe
- https://datascience.stackexchange.com/questions/82765/nlp-what-are-the-advantages-of-using-a-subword-tokenizer-as-opposed-to-the-stan
- https://datascience.stackexchange.com/a/82767
- https://www.linkedin.com/posts/chinmayajena009_ai-llm-nlp-activity-7356005592487878656-5vKn
- https://www.linkedin.com/pulse/language-ai-why-tokens-matter-more-than-words-sascha-wolter-jqpse
- https://codesignal.com/learn/courses/2-modern-tokenization-techniques-for-ai-llms/lessons/byte-pair-encoding-bpe-subword-tokenization-1
- https://www.fast.ai/posts/2025-10-16-karpathy-tokenizers
- https://www.traceloop.com/blog/a-comprehensive-guide-to-tokenizing-text-for-llms









