
Large language models may look impossibly complex, but many of their hidden behaviors can be studied using familiar machine learning tools like regression, clustering, and classification.
One thing that surprised me when I started reading interpretability research was how often the analysis relied on relatively ordinary machine learning techniques. I expected entirely new methods designed specifically for giant neural networks. Instead, many researchers use standard statistical tools to uncover internal structure inside language models.
That shift in perspective matters. Mechanistic interpretability is not only about building bigger models or reading raw weights. It is also about using machine learning as an investigative toolkit.
Machine Learning Is Already a Pattern Discovery System

At its core, machine learning is about detecting patterns in data. That idea sounds basic, but it becomes powerful once you apply it inward, toward the model itself.
LLMs generate outputs through huge numbers of interacting operations, but those operations still leave measurable traces:
- activation patterns
- neuron correlations
- representation clusters
- predictable feature directions
- repeated internal structures
Instead of treating the model as magical, interpretability research often treats it as a dataset.
I think this is one of the most important mindset changes for people entering the field. The model is not just an AI system producing answers. It is also a massive collection of statistical signals waiting to be analyzed.
Regression Can Reveal Hidden Relationships Inside Representations

Regression methods are frequently used to test whether specific information is encoded inside model activations.
For example, researchers may extract activations from an internal layer and train a simple linear regression model to predict:
- word position
- part-of-speech categories
- syntactic relationships
- semantic properties
- sentence structure information
If a simple regression model can recover that information reliably, it suggests the representation already contains structured signals related to those concepts.
I find this approach compelling because it avoids dramatic claims. Instead of assuming a neuron “understands grammar,” the researcher asks a narrower question:
Can grammatical information be statistically extracted from this representation?
That framing keeps interpretability grounded.
A useful real-world analogy is a medical scan. Doctors are not directly observing “pain” or “health” inside an image. They look for measurable patterns correlated with those concepts. Regression analysis inside LLMs works similarly.
Clustering Helps Detect Emergent Structure
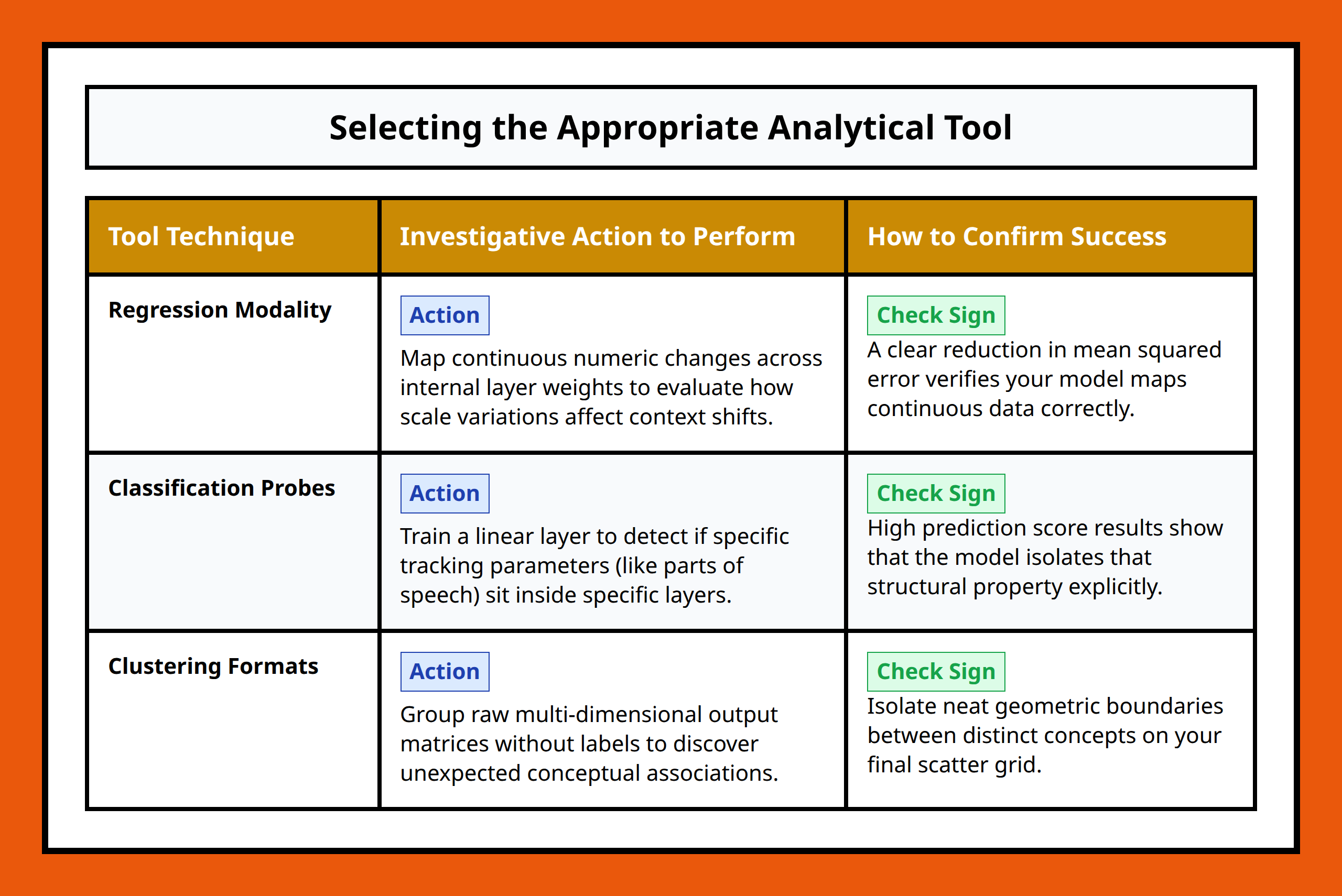
Clustering methods become useful when researchers do not know exactly what structure they are looking for yet.
Instead of imposing predefined labels, clustering groups similar activation patterns together based on statistical similarity.
This can expose surprising organization inside the model:
- similar semantic concepts grouping together
- language families separating naturally
- coding-related tokens clustering apart from conversational text
- syntactic patterns forming recognizable regions
I think clustering is especially important because LLM behavior is often emergent rather than explicitly programmed.
The model was not manually taught “put all adjective-like concepts here.” Yet statistical regularities can still emerge inside the representation space because the training process compresses recurring relationships.
That distinction matters. Interpretability researchers are often discovering structure that was never directly engineered by humans.
Classification Turns Interpretability Into a Testable Question

Classification methods add another layer of practical analysis.
Suppose researchers want to know whether a model internally distinguishes between factual statements and fictional ones, or whether certain neurons activate differently for toxic versus non-toxic text.
Instead of relying on intuition, they can train a classifier using internal activations as features.
If the classifier performs well, it suggests the model representations contain separable information related to the target concept.
I like this methodology because it converts vague interpretability discussions into measurable experiments.
Rather than saying:
“The model seems to understand sentiment.”
Researchers can ask:
“Can sentiment categories be reliably decoded from internal activations?”
That change makes the investigation much more rigorous.
Why Familiar ML Tools Work Surprisingly Well

At first glance, it feels strange that relatively simple methods can analyze systems as large as modern LLMs.
But there is an important reason this works.
Large language models themselves are built from repeated statistical operations. Even though the global behavior becomes highly complex, the internal representations still obey statistical structure that simpler models can often detect.
I would compare it to studying weather systems.
No meteorologist expects a simple equation to fully explain a hurricane. But smaller analytical tools can still reveal meaningful pressure systems, temperature relationships, and recurring patterns inside the larger complexity.
Interpretability research works similarly. Regression, clustering, and classification are not replacing the LLM. They are probing it.
Interpretability Is Closer to Scientific Investigation Than Debugging

One mistake I made early on was imagining interpretability as ordinary software debugging.
Traditional debugging assumes there is a clean chain of logic to inspect. LLMs do not behave that way.
Their capabilities emerge from enormous distributed interactions across high-dimensional spaces. That makes the investigation process feel more like scientific experimentation than reading source code.
Researchers form hypotheses, run probes, analyze activations, compare patterns, and test statistical relationships.
I think this explains why machine learning methods fit interpretability so naturally. They were already designed to discover structure inside noisy, high-dimensional systems.
The Goal Is Not Perfect Transparency
Another useful insight is that interpretability does not require complete understanding of every parameter.
The goal is often more practical:
- identify reliable patterns
- discover recurring mechanisms
- map meaningful representations
- understand failure modes
- predict model behavior more accurately
That makes the field feel much more approachable to data scientists and ML practitioners.
You do not need entirely new mathematics to begin studying LLM behavior. Many of the core tools already exist. What changes is the scale of the system and the creativity required to design useful probes.
And honestly, that is what makes the field interesting to me. The challenge is not inventing magic interpretability algorithms. It is learning how to ask good statistical questions about systems large enough to hide their structure in plain sight.
References:
- https://medium.com/d-classified/utilizing-generative-ai-for-reverse-engineering-31cbcd435e84
- https://community.openai.com/t/reverse-engineer-creative-answers-through-step-by-step-in-reverse/926858
- https://www.reddit.com/r/LLMDevs/comments/1g97fis/how_to_reverse_engineer_llm_weights/
- https://www.reddit.com/r/LocalLLaMA/comments/1kpgla3/reverse_engineer_hidden_featuresmodel_responses/
- https://arxiv.org/html/2604.27319v1
- https://neurips.cc/virtual/2025/poster/116630
- https://blog.talosintelligence.com/using-llm-as-a-reverse-engineering-sidekick/
- https://yliu48.github.io/files/2025/AAAI_2026_Camera_Ready.pdf
- https://www.reddit.com/r/AskProgramming/comments/1ds6hxt/in_theory_can_any_machine_learning_model_be/
- https://www.reddit.com/r/AskProgramming/comments/1ds6hxt/comment/lb0ajpn/
- https://ringzer0.training/countermeasure25-machine-learning-for-reverse-engineers/
- https://medium.com/@aditya758.hitcsecs2020/stealing-minds-reverse-engineering-machine-learning-models-82dbd32d422e
- https://aclanthology.org/2025.findings-emnlp.395.pdf
- https://www.reddit.com/r/LocalLLaMA/comments/1kpgla3/reverse_engineer_hidden_featuresmodel_responses/msxlrna/
- https://www.reddit.com/r/LocalLLaMA/comments/1kpgla3/reverse_engineer_hidden_featuresmodel_responses/mszja6b/
- https://imacengineering.com/blog/reverse-engineering-process-steps
- https://prosperasoft.com/blog/artificial-intelligence/protecting-ai-from-reverse-engineering-model-theft/









