
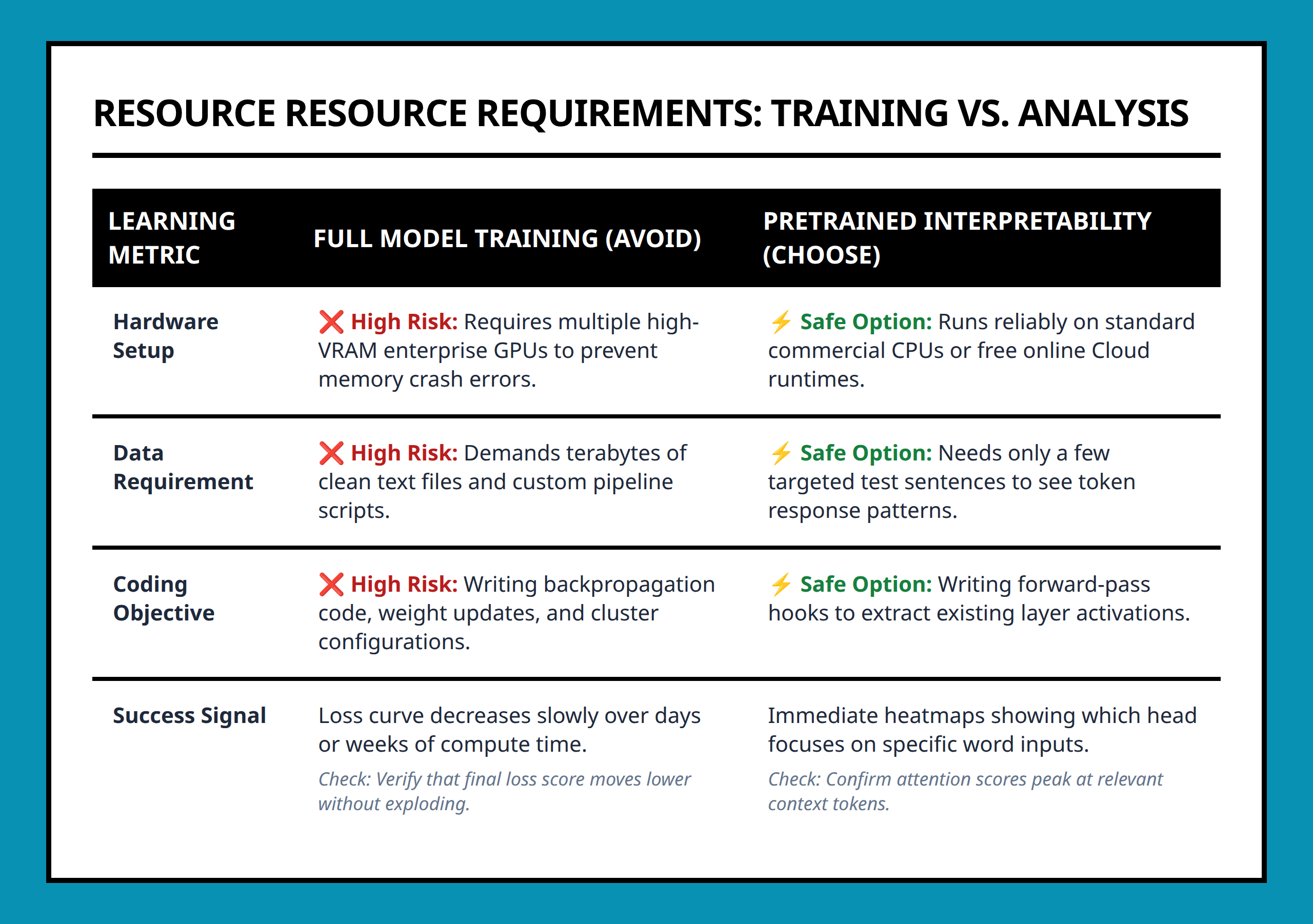
Most foundational interpretability skills can be learned by analyzing pretrained models with lightweight experiments, modest hardware, and practical workflows rather than expensive large-scale training.
One of the biggest misconceptions I see among beginners is the idea that learning LLM internals requires massive GPU clusters and millions of dollars in compute. That assumption stops many people before they even begin.
The reality is much more approachable. Understanding how language models behave is often closer to scientific investigation than industrial-scale model training. In many cases, pretrained models and small experiments are enough to build meaningful intuition about how these systems work internally.
Interpretability Is Different From Training

I think this distinction matters more than beginners realize.
Training a frontier-scale language model is extremely resource-intensive because the system must learn billions of statistical relationships from scratch. Interpretability research, however, usually starts after the model already exists.
That changes the computational requirements completely.
Instead of optimizing trillions of parameters, interpretability workflows often involve:
- extracting activations
- visualizing attention patterns
- probing internal representations
- running small-scale analyses
- testing behavioral hypotheses
Those tasks are dramatically cheaper than full training.
I would compare it to studying a finished airplane instead of manufacturing one from raw metal. Inspection and analysis still require skill, but they are fundamentally different problems.
Pretrained Models Are Enough for Most Early Learning
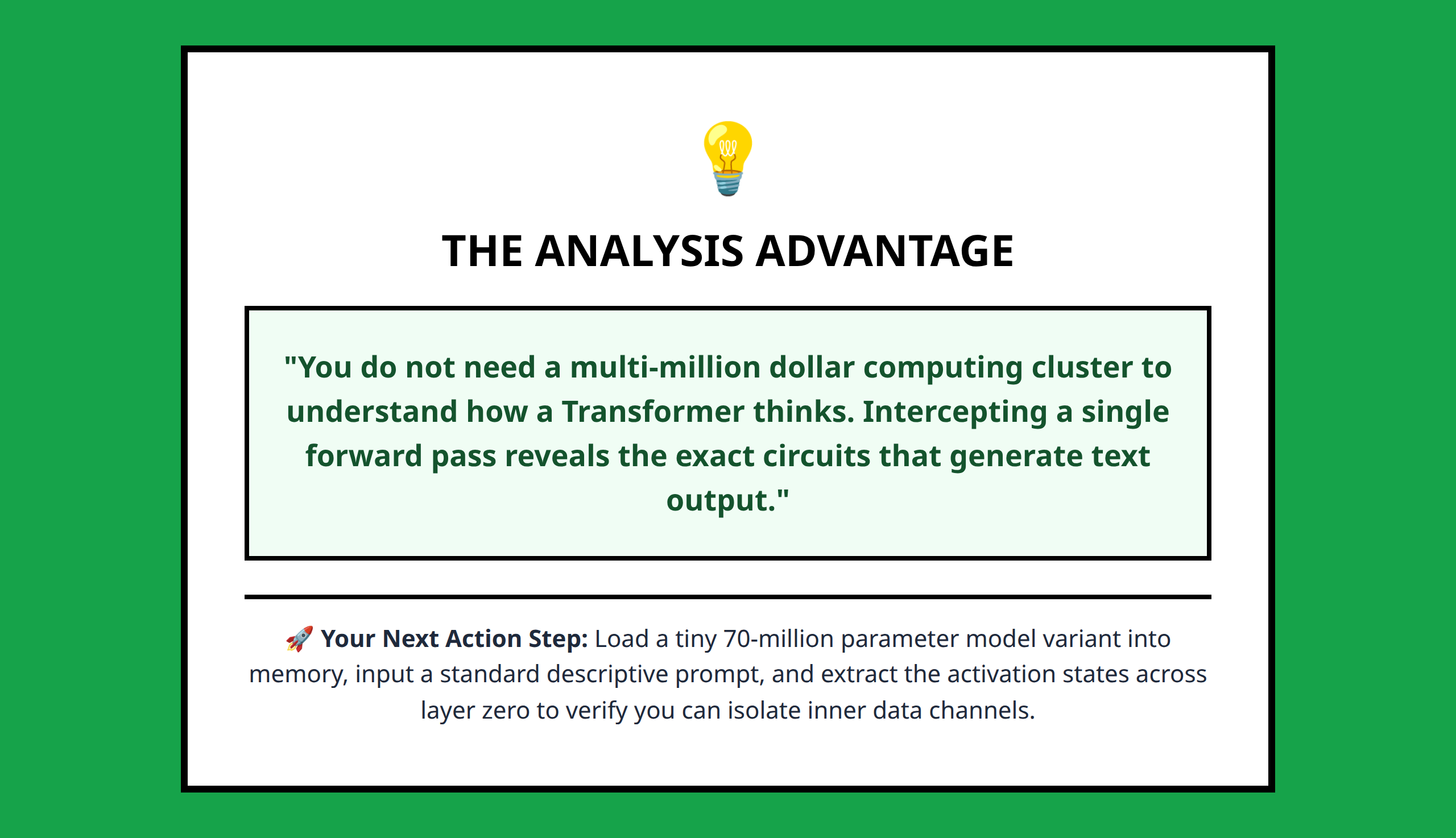
One of the most useful shifts for beginners is realizing they do not need to build models from scratch to learn meaningful interpretability skills.
Pretrained models already contain rich internal structures worth studying.
Even relatively small open-source transformer models can expose:
- attention behavior
- token representations
- activation patterns
- layer specialization
- emergent statistical structure
I think beginners sometimes underestimate how much complexity exists even inside smaller models.
A person experimenting with a modest pretrained transformer on a laptop or in Google Colab can still investigate:
- how tokens evolve across layers
- which neurons activate for specific inputs
- how representations cluster
- how prompts influence internal states
Those experiments build intuition that transfers to larger systems later.
You Can Learn a Lot With CPUs and Free Cloud Tools

Another misconception is that serious interpretability work requires elite hardware from the beginning.
For many introductory workflows, CPUs and free cloud notebooks are sufficient.
Platforms like Google Colab make it possible to:
- run transformer inference
- inspect activations
- visualize embeddings
- analyze token behavior
- test small probing experiments
I would not pretend hardware limitations disappear completely. Large models still create memory and performance constraints.
But beginners often imagine a much higher entry barrier than actually exists.
A realistic learning setup might involve someone opening a Colab notebook after work, loading a small pretrained transformer, and experimenting with token activations using short prompts. That kind of workflow is ordinary now. It no longer requires specialized institutional infrastructure.
The Most Important Skills Are Conceptual, Not Computational

I think people entering interpretability sometimes focus too much on hardware and not enough on analytical thinking.
The harder part is usually learning how to ask useful questions.
For example:
- What information appears to emerge at different layers?
- How do token representations change through the network?
- Which patterns remain stable across prompts?
- What kinds of structures can simple probes detect?
Those questions rely more on reasoning and experimentation than brute-force compute.
A beginner who carefully studies a smaller model often develops stronger intuition than someone who merely runs giant training jobs without interpretability analysis.
You Do Not Need Advanced Math to Start
I would also be careful about overstating the mathematical barrier.
Some interpretability research absolutely becomes mathematically sophisticated, especially around optimization theory or representation geometry. But foundational exploration can begin much earlier.
Basic familiarity with:
- linear algebra concepts
- vectors and matrices
- probability intuition
- Python programming
- basic machine learning ideas
is often enough to start running meaningful experiments.
I think beginners sometimes delay hands-on work because they believe they must first master every mathematical detail. In practice, experimentation itself often motivates deeper learning later.
Small Experiments Teach More Than Passive Reading
One pattern I keep noticing is that interpretability becomes much clearer once people start interacting with real model behavior directly.
Reading explanations helps, but small experiments create a different kind of understanding.
For example, a beginner might:
- compare activations for related prompts
- inspect token embeddings visually
- test how neuron activations shift across contexts
- observe how internal representations cluster semantically
Those exercises make abstract ideas concrete.
I think this is why lightweight interpretability projects are so valuable. They shorten the distance between theory and direct observation.
The Workflow Is Closer to Research Exploration Than Engineering Scale
Another important point is that interpretability workflows are often iterative and exploratory.
You do not necessarily start with a giant infrastructure plan. More commonly, the process looks like:
- form a small hypothesis
- run a targeted experiment
- inspect the outputs
- adjust the question
- repeat
I think that makes the field surprisingly accessible.
The limiting factor is often curiosity and persistence rather than hardware budgets.
A person with modest resources but strong analytical habits can still learn a great deal about how language models organize information internally.
The Real Entry Barrier Is Usually Psychological
Honestly, I think the largest obstacle for many beginners is not technical at all.
It is the assumption that modern AI research is inaccessible unless you already have industrial infrastructure, advanced credentials, or expensive hardware.
Interpretability research does involve difficult concepts, but many foundational skills can be developed through pretrained models, free cloud tools, and small experiments.
And in some ways, starting small may even help. Smaller workflows force people to focus on representations, patterns, and mechanisms rather than treating scale itself as the explanation.
That mindset turns out to be much closer to real interpretability research than many beginners initially expect.
References:
- https://www.youtube.com/watch?v=-Ll8DtpNtvk
- https://www.youtube.com/watch?v=U07MHi4Suj8
- https://www.youtube.com/watch?v=Zar2TJv-sE0
- https://www.reddit.com/r/datascience/comments/1ge7e91/the_best_way_to_learn_llms_for_someone_who/
- https://www.reddit.com/r/LLMDevs/comments/1imwn1y/where_to_start_learning_llms_any_practical/
- https://www.reddit.com/r/learnmachinelearning/comments/1b4iwvl/a_free_roadmap_to_learn_llms_from_scratch/
- https://medium.com/data-science-collective/the-complete-llm-mastery-course-from-zero-to-production-hero-6a2d2720cd6f
- https://towardsdatascience.com/how-i-studied-llms-in-two-weeks-a-comprehensive-roadmap-e8ac19667a31/
- https://rasa.com/blog/llm-training
- https://www.kaggle.com/questions-and-answers/559884
- https://arxiv.org/html/2406.00606v2
- https://www.heavybit.com/library/article/train-LLM-on-own-data
- https://magazine.sebastianraschka.com/p/coding-llms-from-the-ground-up
- https://www.databricks.com/blog/llm-pre-training-and-custom-llms
- https://sanchezsanchezsergio418.medium.com/fine-tuning-large-language-models-llms-techniques-and-best-practices-for-different-use-cases-97fab572a7a9
- https://blog.nobledesktop.com/learn/machine-learning/can-i-learn-machine-learning-on-my-own









